Nothing will break if you don’t log retriever traces in the correct format and data will still be logged. However, the data will not be rendered in a way that is specific to retriever steps.
-
Annotate the retriever step with
run_type="retriever".
-
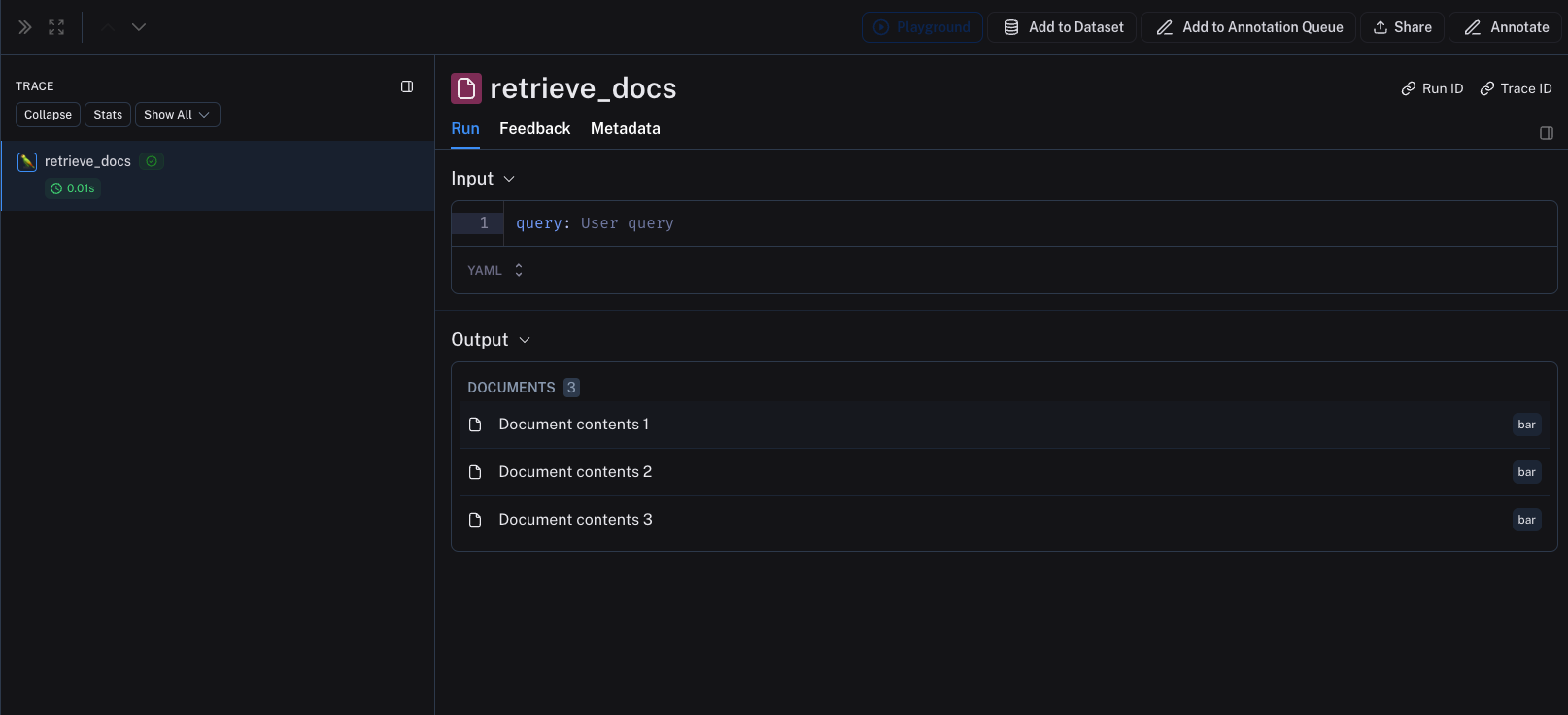
Return a list of Python dictionaries or TypeScript objects from the retriever step. Each dictionary should contain the following keys:
page_content: The text of the document.type: This should always be “Document”.metadata: A python dictionary or TypeScript object containing metadata about the document. This metadata will be displayed in the trace.
The following code snippets show how to log a retrieval steps in Python and TypeScript.
from langsmith import traceable
def _convert_docs(results):
return [
{
"page_content": r,
"type": "Document",
"metadata": {"foo": "bar"}
}
for r in results
]
@traceable(run_type="retriever")
def retrieve_docs(query):
# Foo retriever returning hardcoded dummy documents.
# In production, this could be a real vector datatabase or other document index.
contents = ["Document contents 1", "Document contents 2", "Document contents 3"]
return _convert_docs(contents)
retrieve_docs("User query")